人間を空間の中心とする、潤沢で安全な生活環境を実現する
インタラクションには様々な形態のものがあります.本研究室では、主に人工システムを介した人間同士のインタラクション,人間と非人間のインタラクション,非人間同士のインタラクションを主な研究対象にしています (非人間とは機械,ロボット,動物などを含む人間以外のインタラクションが可能なものを意味します).しかし,研究室の名前で分かるようにインタラクション技術を応用したシステムを研究するところなので研究範囲は非常に広く,研究テーマに制限はありません.
研究テーマ現在AIS研究室で行っている研究の一部を紹介します。 |
|
 |
空間知能化(Intelligent Space) 空間を賢くし、人間を支援する研究です。人になるべく負担をかけず、環境側にセンサ、ネットワーク、人工知能など様々なデバイスを分散配置することで空間内の人間を支援することを目指しています。このようなシステムを開発するプロセスを空間知能化、それで出来上がる賢い空間を知能化空間と呼んでいます。空間知能化は様々な要素技術及び機能が必要とされる研究テーマで、様々な小テーマがあります。 |
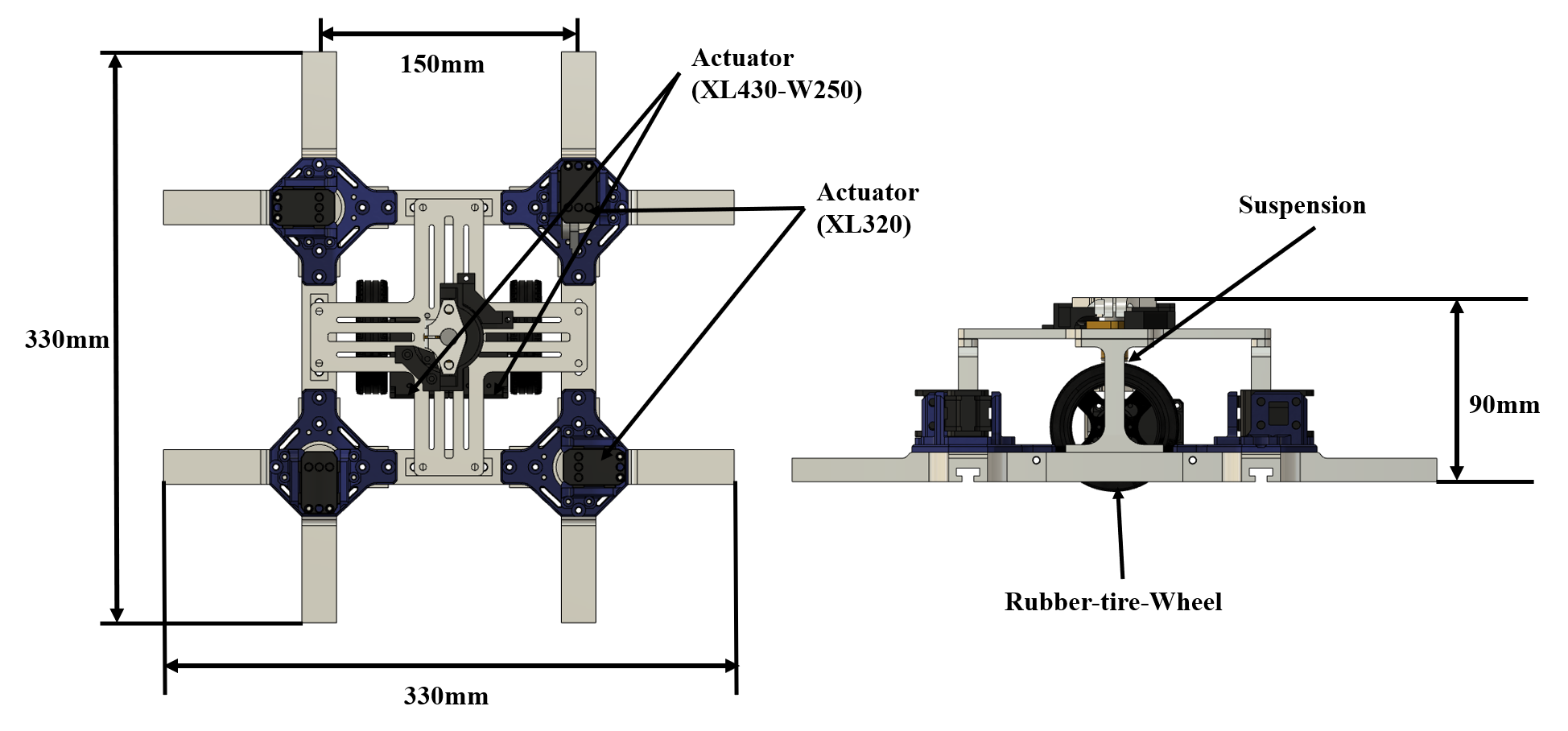
| 再構成可能な知能化空間とMobile Module 従来の知能化空間では、センサなどのデバイスを空間内に配置すると、再配置することが困難となります。 また、最適なデバイスの位置は空間内の状況によって変化するといった問題もあります。 そこで本研究室では、空間内の全てのデバイスをMoMo(Mobile Module)に搭載し、 MoMoが空間内の天井や壁を移動することでデバイスの再配置を行い、常に最適化された知能化空間である再構成可能な知能化空間を目指しています。 |
 |
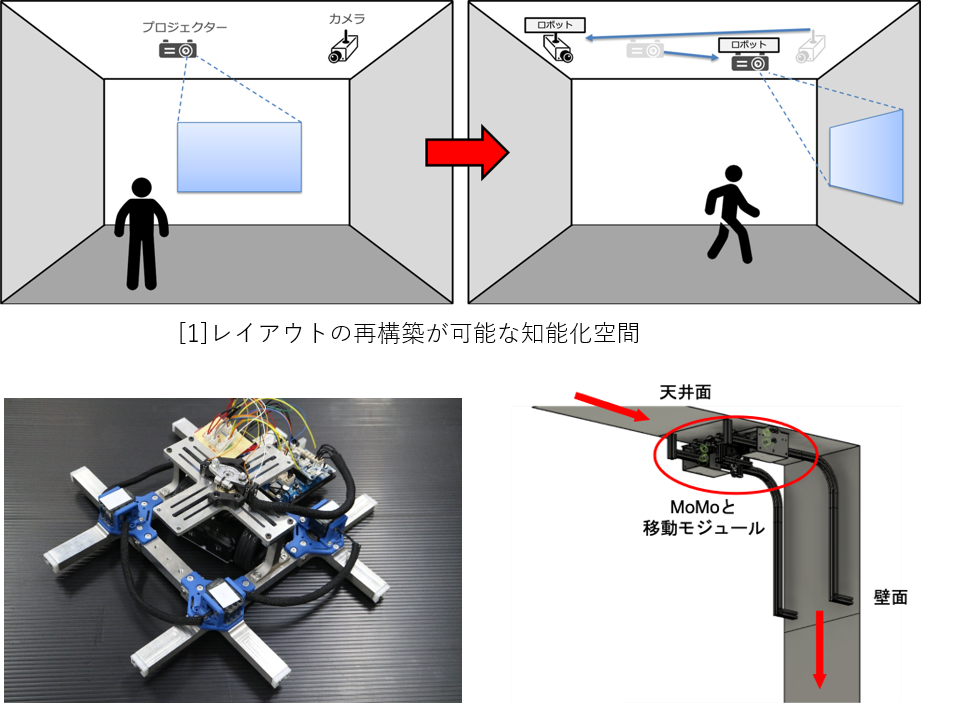 |
壁・天井移動ロボットの別平面への移動機構の開発 近年,IoTの研究が盛んに行われており,このIoTを実現するためには人・ロボット・機器などがネットワークで相互に繋がっている必要がある.知能化空間は,IoTを含む包括的な空間システムである.空間内にセンサ・演算機能・ネットワーク機能を持つデバイスを分散配置することで,人物やオブジェクトの状況を収集し,この情報を基に人を支援することが可能である. しかし,固定されたデバイスによる支援では,空間内の変化に対応出来ない場合がある.そこで,壁・天井を移動可能なロボットMoMo(Moblie Module)[2]を利用することで,デバイス側がユーザにとって最適な位置に移動するシステム[1]が考案された.MoMoは壁に突起,本体にレールを用いることで,自己位置推定の容易化や固定時にエネルギーを消費しない機構という利点があるが,本体にレールを用いた構造上,MoMo単体では,天井から壁といった他平面への移動が不可能な機構であった.そこで,他平面への移動を可能にする移動手法の開発を行っている.別平面の移動手法として,壁自体をモータで90度動かすことで移動を可能にする機構が開発されたが,電力消費や移動機構の小型化に制限があった.この点を踏まえ,MoMo本体に取り付けられたモータの力だけで別平面への移動を可能にする機構[3]を現在開発中である.この機構では,移動時における電力消費を最大限減らすことが出来るだけでなく,MoMo本体の機構に沿った移動が可能となる. |
| 指差しを用いたインタラクションシステム 知能化空間は、ユーザの状態や要求を正しく認識・理解することでサービスを提供してます。 しかし、人の要求は様々であるため、的確に認識・理解することは困難であり、また誤認識により人の意図しないサービスが行われることはあってはなりません。 人同士がコミュニケーションを行うかのように、人とシステムがコミュニケーションを行うことができれば、誤認識は起こり得ません。 本研究では指差しによって示したモノや位置を人とシステムが相互に認識し合うことで、コミュニケーションを行う方法を提案します 。本システムを用いることで知能化空間内にある機器やモノを操作できるようなインターフェースの実現を目指して、研究を行っています。 Youtube Video |
 |
 |
知能化空間における携帯端末を用いたインタラクションシステムの提案 本研究では、知能化空間内でユーザのスマートフォンをインタフェースとすることで、 様々な機器とのインタラクションを実現するシステムR-Fii(Real-world Flexible Intelligent Interface)を提案しています。 ユーザはスマートフォンのカメラを通して機器を撮影すると、機器に関する情報を読み取ることができたり、 操作メニューが表示されてそのまま操作したりすることができます。 このシステムにより、ユーザはスマートフォンを知能化空間における唯一のインタフェースとして、 空間内のすべての機器と一元的にインタラクションを行うことができます。 また、本システムでは、ユーザごとに操作権限を変更することができ、 特定のユーザにはある操作を行わせないことや情報を表示させないといったセキュリティに関する機能も実現しています。 本研究により、知能化空間内で各ユーザが様々な機器と快適なインタラクションを実現できると考えています。 今後は、知能化空間内で得られる情報と組み合わせることで、さらにユーザをサポートすることを目指しています。 Youtube Video |
| マニピュレータによる被介護者の自立生活支援 近年、サービスや施設などの介護環境の充実だけでなく、被介護者の自立生活の支援をどのように行うかが重要な課題となっています。そこで、本研究では日 常的に車椅子を使用する被介護者を対象に、介護総量の軽減を目的としたマニピュレータによる生活支援を提案しています。従来、このような目的を持ったマニ ピュレータは車椅子に固定して利用されてきました。しかし、本研究ではマニピュレータが車椅子から分離し、遠隔操作されることで、従来よりも幅広く日常生 活における不便な場面を支援することができると考えています。このような取り組みは、介護総量の軽減だけでなく、被介護者自身のQOL(quality of life)の向上にも繋がるものと考えます。 |
 |
 |
人間を中心とした情報提示を可能とするUbiquitous Displayの研究 本研究室では、これまでにない新しい情報提示装置、Ubiquitous Display(UD)の研究開発を行っています。 UDとは、可動式のプロジェクタを搭載した移動ロボットのことです。 この機構により壁や床・物などのあらゆる場所にプロジェクタで画像を投影することによってディスプレイを作り出すことができます。 さらに、人間を中心とした情報提示の実現を目指し、人間の位置や視線の情報に基づいて、最も効果的な場所に情報を投影します。 また、実際に存在する物に対して映像を被せるように投影することによって拡張現実感(AR)などを人間が特殊な装置を装着することなく実現可能になります。 UDの詳細な紹介 |
| マルチカメラ画像を利用した手術ワークフロー分析に関する研究 現在, 医療機関において, 画像認識技術を活用した研究が進んでいる. 未来の手術室には,リアルタイムワークフロー分析, 及び医療判断決定支援システムの2機能が必要である. なお, ワークフローとは特定の活動が特定の順番でなされるものである. このうち, 特にリアルタイムワークフロー分析に関連した研究分野として, 手術室内の活動認識を行う研究が多数行われている. これらの研究の目的は, 病院の手術の効率化にある. 特に一日に複数回の手術が行われるような大病院にとって, 手術はその一度のみを考えるのではなく, 複数の手術において, 患者の搬送や麻酔のタイミングといった問題が絡んでくる. そのため, 手術の状況を現場の医療スタッフだけではなく, 病院全体で把握することで, 病院内で手術計画を立てやすくなり, 病院全体の業務効率化につながる. 他にも, このワークフロー分析により手術のサポート, 手術シミュレーション, 手術後ドキュメントの自動作成などが可能となる. 本研究では、画像処理を用いて、リアルタイムワークフロー分析に取り込んでおり、達成時に医学的な有用性があると考えられる. Youtube Video |
  |
 |
Wearable Robot Arm ー 人の作業を支援すあるロボットアーム 人にロボットアームを装着し作業を支援してもらうことで,人の作業効率が向上し,2本の腕ではできなかった作業が可能となり,人の能力が拡大する.そこで,ロボットアームを人に装着し,3本目の腕としてタスクのサポートを行えば,人の能力拡大に繋がると考え研究を行っている. 人に装着するロボットアームとして最も解決すべき問題が2点挙げられる.1つ目は軽量であることである.ロボットアームの重量が重いと人に直接負担がかかり,作業時間や作業効率に支障が出る.2つ目は,安全である必要がある.従来のロボットアームはすべての関節を人がコントローラを用いて,モータを操作する.しかし,この操作方法では人の誤操作でロボットアームが人に衝突し事故や怪我が発生する可能性が高い. 主に,この2点に着目し,軽量で安全な装着型ロボットアームを開発し研究している. |
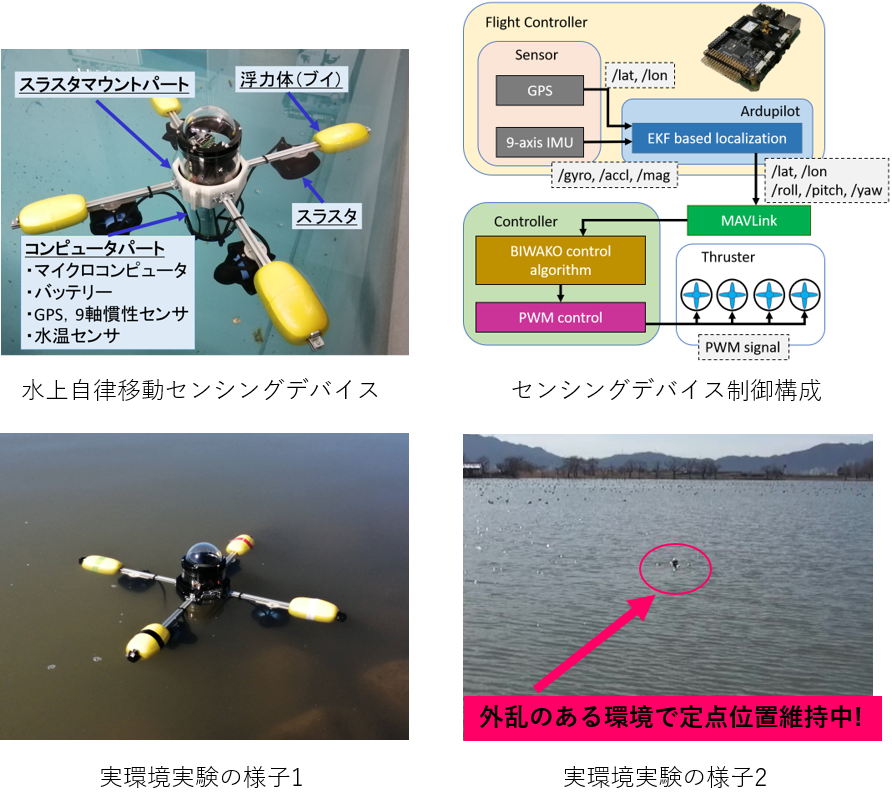
| 長期水上環境観測システムの構築 海洋や湖沼における水質汚染,生態の変化など,水圏の問題が注目されている.これらの問題に対して,センシングデバイスを用いて水上や水中の長期的な環境データを定点観測することで解決しようという研究がある. これまでさまざまな場所で観測が行われていたが,水上において位置を保ちながらデータを観測し続けることは波や潮流などの外力の影響により,困難であった. 本研究ではセンシングデバイスをアクチュエータの駆動のみによって水上の同じ位置を保ちながら,連続的に環境データを観測し続け,観測したデータをUAV(Unmanned Aerial Vehicle)で回収する,水上定点観測システムについて研究する.センシングデバイスはGPSやIMUセンサなどにカメラ画像を組み合わせることによって,位置を保てるようにする.観測の対象は水質,水温,降雨量,水上の画像データなどを想定している.観測した環境データを分析することによって,琵琶湖の長期的な環境データ観測に貢献させる. |
 |
 |
介護動作の定量的評価を目的とする介護練習用ロボットの開発 介護訓練のための老人ロボット·シミュレーターは,高齢者の割合が持続的に増加することから重要な役割を果たしている.介護士が介護動作を習得する最も良い方法は実際の高齢者に対して介護動作訓練することであるが,訓練生が実際の高齢者に対して訓練するにはケガを負わせるなどリスクがある. そこで本研究では,介護訓練生の介護動作を定量的に評価できるようにすることを目標として,被介護シミュレーションロボット(CaTARo: Care Training Assistant Robot)を開発している.CaTARoの各部には様々なセンサが搭載されており,介護訓練生の介護動作の正確性をリアルタイムで計測するモニタリングプログラムを備えている.これまでにCaTARoのひじ関節および肩関節を開発している. 被験者実験では,介護初心者と熟練者のひじの外部関節角度,ひじにかかるトルクおよび手首にかかる圧力といった定量データを取得し,初心者が熟練者のデータを追従することで適切な介護訓練ができることを検証した. Youtube Video |
| Autonomous navigation system in search operations for object deployment and collection using a UAV This work proposes an autonomous navigation system for deployment and collection of objects by the use of UAV. To collect and deploy an object autonomously using a UAV, the system can navigate autonomously by calculating a travel trajectory using Coverage Path Planning techniques. While navigating through the calculated path, image processing is implemented to search for a designated target. The UAV navigates throughout the calculated path until the specified target has been found or the entire area has been covered. Human interaction is not required during the entire process. |
 |
 |
ウェアラブルカメラを用いた周辺環境復元と行動認知 近年,GoProなどのウェアラブルカメラを録画し続けたまま,日常の行動や観光などを記録する人が増えている.その際,データ量が膨大になることや,データを振り返ることが大変になる問題点がある.そこで,本研究ではユーザに装着されたウェアラブルカメラを使用して,日常の行動などを記録した大量のデータから,装着者が注目した場所・対象を推定することで,効率的な映像記録の利活用を実現することを考えている.人が注目する対象を推定する方法として,指差しという行動に着目し,指差し方向を推定するとともに,周辺環境の3次元復元を行うことで,ユーザが注目している物体・対象を推定する. 以下の方法により,ユーザの注目対象の推定を行う. 1.ウェアラブルカメラを用いた周辺環境の3次元復元 胸部に装着したウェアラブルカメラより,装着者及び周辺の環境を同時に観測する. |
| 環境とのインタラクションにおける人の視認推定とその応用 近年,日常生活で扱うべき情報が飛躍的に増加している.そして,人は情報の大半を視覚から得て,行動を決定している.そのような世の中で視覚情報取得を支援することは多くの人に役立つと考えた. 例えば,高齢者や小さい子供など視覚情報を上手く取り込むことができない人の支援ができれば,交通事故の回避や円滑なコミュニケーションに役立つ.また,学校の先生や介護者,カウンセラーに生徒や被介護者の情報取得状況を可視化して伝えれば,情報取得を支援する人への支援へと繋がる.そして,人に対してだけでなく,電子看板や広告,カーナビなどのコミュニケーションツールやロボットにユーザの注意・興味に応じた情報呈示を行えば,情報伝達ツールの支援にも役立つ. 本研究では視環境の動的な変化と視線の動きの関連性から人の視認状態を推定する手法を確立し,さらに視認推定による人の内部状態把握を実際の場面でのインタラクション支援へ繋げる.視認推定結果が様々な想定場面で適応可能かを実験を通して検討し,将来,人間が日常生活の中で情報を取捨選択する際に役立てる. |
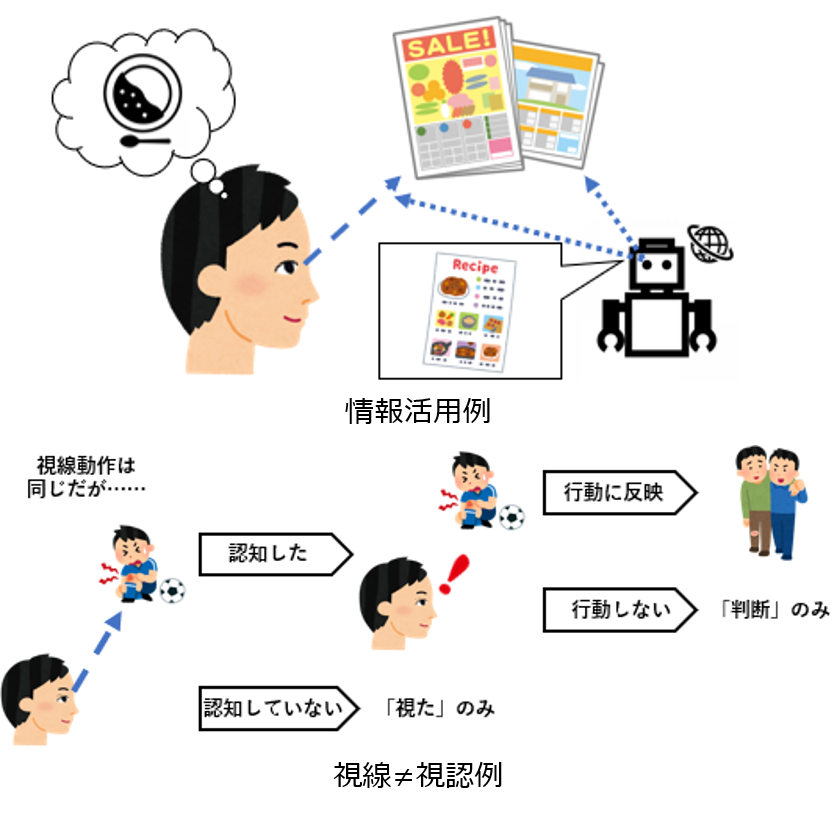 |
 |
自動運転システムにおける搭乗者状態の推定と行動誘発手法の検討 近年,高齢者の自動車運転による事故率が増加している.そのため,自動運転を行い人のミスによる事故を削減する目的の研究が活発に行われている.実際に自動運転技術が搭載された車が発売される中,万が一の場合には自動運転から人間に操作権限をスムーズに戻す必要がある.本研究では,その万が一に備えた自動運転システムにおける搭乗者状態の推定と行動誘発手法を検討している. 自動車運転の自動化が進むと搭乗者が行う操作の頻度は減少し,ハンドルやペダル等の操作量から搭乗者の状態を推定することが困難となる. この問題を解決するために,搭乗者の運転操作に頼らずに計測可能な情報,眼球や頭部の運動などの身体動作,脳波や脈拍などに基づいた推定方法を確立する必要があり,その状態に対応した誘導で適切な行動を喚起する方法を提案し検討する. 適切な行動誘導では,搭乗者の状態により,自動運転レベルを操作することで安全な運転が維持できることも視野に入れている. |
| ウェアラブルロボットのための腕上移動機構の開発 近年,パートナーとしてユーザに適切な情報伝達を行うことや,安心感を与えるなどのインタラクションを目的としたウェアラブルロボットの研究がされている.しかし,これらは体の一部に固定されており,装着位置が限定されている. そこで本研究では身体上を移動可能なウェアラブルロボットを提案することを目指す.その最初の段階として,腕に装着して移動するための機構を開発する. 移動ができることで,図のようにユーザが歩行や起立状態である場合には肩付近まで移動し,着席状態である場合には手首付近に移動してインタラクションを行うといったように, ユーザの姿勢に応じて適切な場所に移動し,ロボットの位置に応じたインタラクションを行うことが可能となる.これにより,より効果的なインタラクションが可能になると考えている. |
 |
 |
外骨格を用いた握力増強装置の開発 外骨格とは,図のように手に直接装着する人工の骨格のことで,手の動きをサポートしたり,現在の手の状態を,数値化することができるものである. 工事現場では仕事中の怪我や事故が後を立たない.年間1500人もの人が亡くなっている.その死亡原因として墜落と飛来落下が約50パーセントを占めている. そこで今回の目的は,握力を増強することによって,高所での作業中に,手すりにつかまりやすくしたり,物を落とさないようにすることである.さらに長時間の作業による筋肉疲労のよる事故を防ぐことができる. そこで本研究では,センサを用いて自分の意図した動きにできるだけ近くなるようにアルゴリズムを作成すること,できるだけ軽くすること,扱い易いデザインにすることを目標に研究します. |
| プロジェクタ搭載ドローンによる夜間警備システム 人間による警備業務は,長時間労働や夜間勤務を前提としたものであり,負担の大きい職業として知られている.また,新しい施設の増加などから,警備業は深刻な労働力不足に陥っている.このことから近年,車輪型やドローンといった様々な警備ロボットが誕生している.しかし,車輪型ロボットには段差や人などの障害物に対応できないこと,ドローンには夜間警備を対象としたものがないことや警備対象者からのインタラクションを行えないなどの問題点が存在する. 本研究では,人や段差などの障害物の影響を受けず,空から広域の警備を可能とする警備ドローンAUD(Aerial Ubiquitos Display)を作成している.AUDには,夜間における警備を可能にするため赤外線カメラを搭載している.このカメラを用いて人間の行動を検出し,接近する.また,ドローンに小型のプロジェクタを搭載することで,人間がドローンから投影された情報を読み取るインタラクションを可能にしている.このシステムが完成すると,大学内で巡回している警備員の代わりを担い,人件費の削減や軽微業務の負担軽減を実現化することが可能になる. |
 |
 |
影生成ロボットDeSCaRo(Deformable Shadow Casting Robot)における影生成アルゴリズムに関する研究 本研究では,ロボットを用いて影絵をどのように作成するかの研究を行っている.影絵を作成するためにDeSCaRoというロボットを作成した.図1のように, DeSCaRoは4重円の回転ベースの上にアームが一つずつ設置されており,アームとベースで制御が異なる.一つのアームは8つのモータで構成され,図2のように,X軸方向Y軸方向に回転するモータが交互に接続しており,それぞれ左右に90度ずつ,計180度回転する.生成したい影絵により,アームの位置と形状を決定する. 現段階では影絵を生成するために,ユーザが直接形状を決定しなければならない.そこで,機械学習を用いてDeSCaRo自身に目標とする影絵の画像を読み込ませ,目標形状を決定し,光源の位置,影の投影場所,ロボットの位置などを考慮して自動的に変形させるための最適なアルゴリズムを提案する.これにより,ユーザが直接にする入力することなく,自動的に影を生成することが可能になる. |
| 階段昇降が可能な配達クローラ型移動ロボットの機構に関する研究 ネット通販が多く利用されることをはじめ,宅配サービスは発展する傾向にあった.しかし,業務量の増加及び多頻度小口配達で物流の効率が下がり,配達のコストが増大する問題も発生している.さらに,現在は新型コロナウイルスの感染が拡大している影響で,人との接触を極力避ける傾向にある. 今まで活用されているエレベータと連携できる配達ロボットもあったが,エレベータと通信する為には建物そのものを工事する必要があり,追加建築費用が増大する. 上記の問題を解決する仕組みの一つとして,本研究では階段昇降でフロア間移動することができ,小型の構造を有する配達クローラ型移動ロボットUDOn(Ubiquitous Delivery On-demand Robot)を開発した.なお,サブクローラではなく,電動シリンダーによる階段昇降手法を提案した. 今後は階段昇降を行う時の方向修正機能や障害物の回避機能も実装する予定である. |
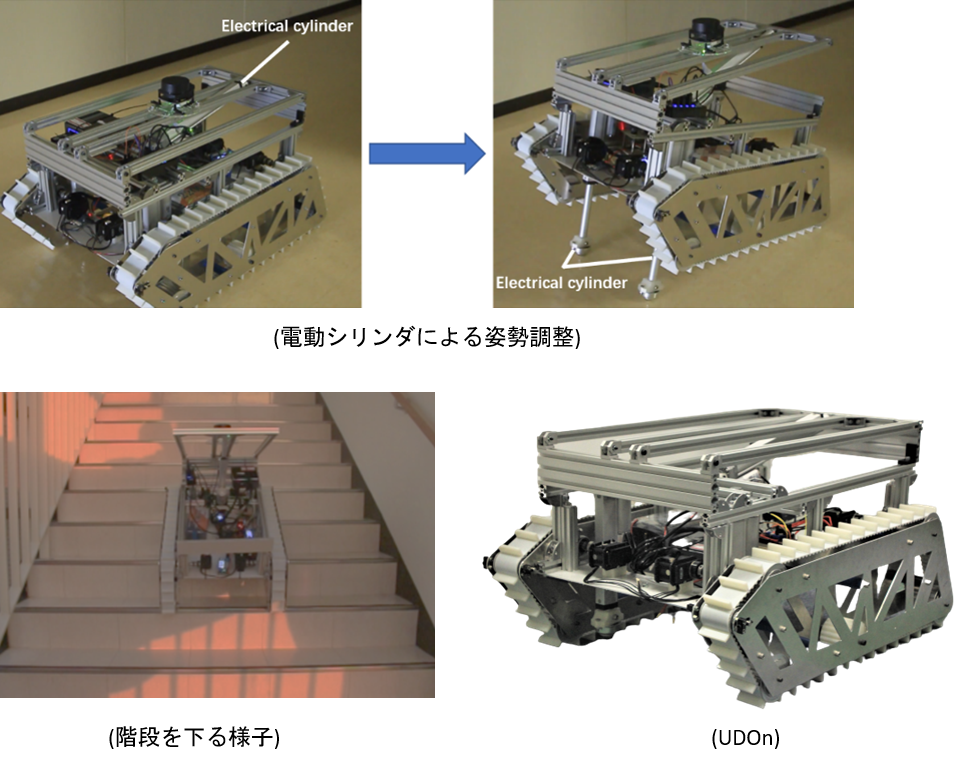 |
 |
複層建物におけるクローラ型宅配サービスロボットの自律移動 近年,コロナウイルスの影響により外出自粛・自宅待機が強いられるようになったため,オンラインショッピ ングの利用数が増加した傾向が見られた.それに伴って宅配業者の仕事量も増加しているため,宅配作業をサポートするロボットの研究開発を行った.これまでにも数多くの宅配サービスロボットが開発されてきたが,そのほとんどが屋外移動に向けて開発されたものが多く,複層建物に向けて開発されたものは,フロア間移動をエレベータとの通信を行う必要があるため,建物自体にも工事を必要としコストがかかる.そこで,本研究ではクローラ型移動基盤を用いた階段移動によってフロア間移動を行う宅配サービスロボット(名称:UDOn)の開発を行った. 本研究では,主にUDOnは階段に乗り上げる際,クローラ部に取り付けられた2本のアクチュエータによって機体を持ち上げるため,それらの制御を行い階段昇降を実行するプログラムの作成及び,これらの階段昇降と自律移動を組み合わせる手法に関する研究を行ってきた.本研究の実験では,階段昇降時の自己位置推定に関する調査を行い,本実験はシミュレーション環境と実世界環境にて行った. 今後はこれらの実験を基に,よりスムーズな階段昇降を可能とする自律移動機能にしていくこととなる. |
| 半自律型移動ロボットを用いた3次元モデルの自動生成システム 自律移動型ロボットによる物の運搬や,ロボットアームによる車や食品等の生産過程の自動化など,今まで人が行っていた作業をロボットに任せる「自動化」技術は時代と共に需要が高まっている.また現在,3Dゲームや物理演算等のシミュレーション環境において3Dモデルが頻繁に使用されており,現実空間にある物体を3Dモデルに変換する3Dスキャナも広く活用されている.既存の3Dスキャナは手持ちタイプと設置タイプがあるが,物体をスキャンする際に「現地に赴く」,「歩き回って撮影する」,「スキャナを設置する場所が必要」等のコストがかかってしまう. そこで私はスマホで遠隔操作可能な移動ロボット[1]を使用し,離れた場所から少しの操作で物体の3Dモデルを生成することができるシステムを提案する.本システムにおいてユーザはスマホに映し出されたロボット映像から物体をタップすることによりロボットは自律移動で指定された物体の撮影し,3Dモデルを生成する.移動できるロボットに作業させることで固定場所の制約を無くし,ユーザはスマホで楽に作業を行うことができる.これにより今までユーザにとって手間であった撮影コストの大幅な削減が予想される. |
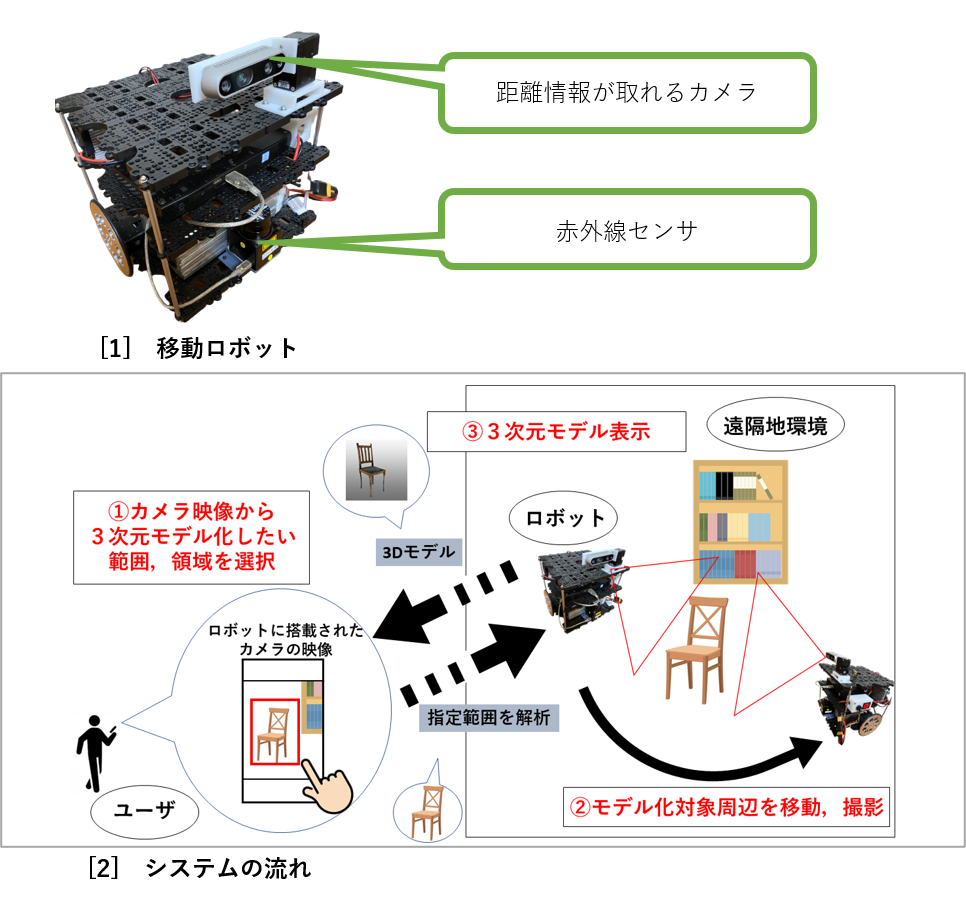 |
 |
対面ゲームにおけるテレプレゼンスロボットの開発 近年,新型コロナウイルスの影響によりリアルタイムでの対面が難しくなっている.それに伴い,コンピュータを使用しないアナログゲームをプレイすることも困難となっている. また,アナログゲームは人数制限を設けているものも数多く存在し,その性質上,同じ場所に居合わせる必要がある.そのため,その場に居合わせる人数の少なさから遊戯できないことや,遠方にいることで遊戯に参加することができない等の問題がある. このような問題を解決すべく,本研究では,遠隔操作が可能なテレプレゼンスロボットを実装することで遠方にいるユーザがアナログゲームに参加できるようにする.また,本研究では数あるアナログゲームのうち,複数人でプレイする必要があり,世界的にポピュラーなアナログゲームの1つである麻雀を採択した.麻雀をプレイする際に必要となる基本的な動作をテレプレゼンスロボットに行わせる.加えて,実装するテレプレゼンスロボットを用いてプレイする人と,複数人のリアルタイムでプレイしている人を同じ麻雀卓で遊戯させることで,人間の代わりにアナログゲームをプレイすることが可能かを検証する. |
| ユニバーサルデザインを考慮した自律走行可能なPMに関する研究 近年,環境に優しいPM(Personal Mobility)が注目されている.PMとは1~2人乗りの10km前後走行する乗り物と定義される.現在研究されているPMは,老若男女問わずに乗れるものは少ない.そこで本研究では,誰でも楽しく乗れるようなPMを目指して研究を行っている. 誰でも楽しくPMに乗れるようにするためには,ユーザビリティとユニバーサルデザインを考慮する必要がある.ユーザビリティとは,誰でも簡単に操作できることであり,ユニバーサルデザインとは,誰もが乗りたくなるようなデザインである.本研究では,ユーザビリティ面に着目し,ユーザの足または手で操作可能なPMを研究開発した. 現在は新たなPMの開発を行っており,誰でも楽しく乗れるPMの研究開発のために,ユニバーサルデザインの検討と,ユーザビリティの更なる検証をする.また,自律走行機能を搭載し,ユーザのもとに近づく機能や目的地に自律走行する機能を搭載する予定である. |
 |
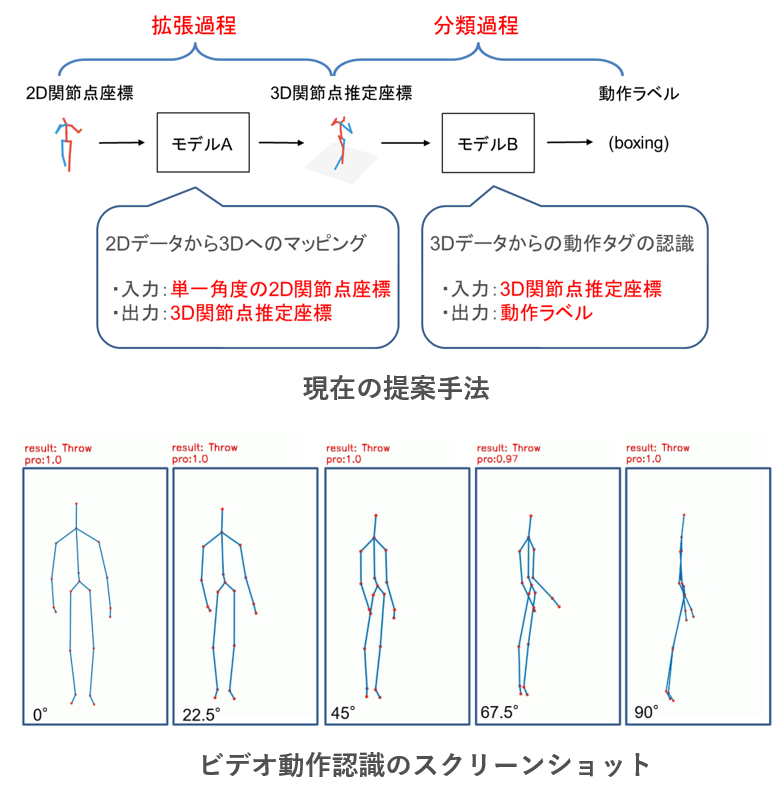 |
人間の2D関節点座標に基づくカメラ視点変化にロバストな動作認識 携帯機器の計算力やデータ転送能力の向上に伴い,顔認識,目標検出などの応用が普及し,人体動作認識に対する需要が高まっている. 本研究では,動作認識技術の1つである2D関節点データからカメラ視点の変化に堅牢な人間の動作認識を行う. 2D関節点データはRGB カメラで容易に取得できるが,深度情報が乏しいため,カメラ視点が変化すると関節点情報も大きく変化してしまう.そのため,学習するためにより多くののデータが必要であり,できるだけ多くの角度の動作情報を含むことで,モデル認識の精度を高める必要がある.しかし,実験ではなく実用化した場合,ビデオ中の人物のすべての角度の動作情報を得ることができないため,データセットを拡張することが困難であり,実用化することも困難である. 逆に2D データの深度情報欠落の問題を解決できれば,2D データによる動作認識の実用性を向上させることが可能である.そのため,本研究は拡張2D 骨格データに基づく動作認識手法を提案し,その可能性の検討を試みる. |
| 人間の2D関節点座標に基づくカメラ視点変化にロバストな動作認識 近年、画像処理技術の発展により、3DCG 技術が日常社会の様々なところで用いられて いる。例えば、ゲームや映像などのエンターテインメント分野や日本のアニメーション分野 などが挙げられる。日本のアニメーション分野においても、3DCG 技術は日常社会の様々なところで用いられている。3Dアバターの作成や3Dアバターのモーションの作成は、より複雑なものが求められている。そのため、作成にはとても時間がかかり、制作費用が高くなっている。 3Dアバターを動かす方法は、トラッキングやモーションキャプチャ等様々な方法があるが、高度な動きをアバター上でモーションとして実装するには、制作環境に沢山の費用と時間をかける必要がある。そのため、本研究では、上記のような複雑な機材を使うことなく、会話の音声や、会話の文章などから、3Dアバターのための人間らしいモーションデータを作成することを目標に研究を行っている。 この目標を達成するために、人の会話の音声や文章から、人の動きに関する様々な情報をどのようにコンピュータに理解させるかの検討や、会話の文章情報が持つ感情の推定などを行い、 表情の生成などを行っている。 |
|
 |
RGBDカメラを用いた知能化空間内のVR化に関する研究 新型コロナウイルスの影響でオンライン会議の利用が活発になっている.しかし,対面で会話する場合とオンライン上で会話する場合とでは相手から受ける印象が異なる.VR空間を用いたコミュニケーションの手段はVRChat.incのVRChatが挙げられる.しかしこのアプリケーションでは既存のVR空間を利用しているため,オンライン会議のような実際にカメラで写す場合とは違い,自身の周囲の環境を描画できず,実空間の情報を伝えづらい.例えば関連研究で行われたような,相手が存在する実空間の物体を指して話題の種にすることは難しい. そこで本研究ではRGBDカメラと呼ばれる,画像とカメラからの距離を取得できるものを普段生活を送っている空間に設置し,その空間をベースにしたVR空間を構築する方法を考案する.この方法によって,日常生活を送っている部屋がリアルタイムでVR空間化できれば,通信技術と組み合わせることで,VRChatのように対面で会話している感覚と実空間の情報を合わせもったアプリケーションを開発することが可能である.そしてこのようなアプリケーションがあれば新型コロナウイルスの影響下であっても,遠隔地にいる人物との擬似的な対面が可能となる. |
| 歩行者群モデル分析のための人物追跡及び軌跡エディタに関する研究 建物や障害物の位置から人の流れを解析し,混雑しないスムーズな流れを作る研究が行われている.まず,人の流れを解析するためには,人物の動きを動画像から捉え,歩いた軌跡を表示しなければならない.そのため従来手法では,手作業で数フレームずつ人物を追跡し軌跡を表示してきた.しかし,手作業で行うため,精度は良い反面,非常に時間と労力を費やす. 画像処理分野では,人物追跡及び軌跡表示のアルゴリズムを用いて自動で行う研究がある.しかし,手作業とは反対に時間や労力は費やさないが,精度が良くない場合があり正確な追跡及び軌跡表示を行うことが出来ない. そこで本研究は,自動で人物追跡及び軌跡表示を行ったあと,使用者が簡単に軌跡を修正できるエディタの開発を行った.自動である程度,追跡及び軌跡表示を行った後,間違っている軌跡を簡単に修正でき,従来手法より速く軌跡表示が可能となった.図の上側が自動のみで追跡及び軌跡表示を行ったときであり,下側がエディタを使用して軌跡を修正した後である. |
 |
 |
動作識別に基づいた効果音再生システム 本研究は、人が体を動かすことで、自在に音楽を奏でることのできるシステムを提案します。 例えば、鋭い動きをすれば鋭い音を鳴らすことができ、柔らかい音を奏でるには柔らかい動きをとればよいという風に、イメージした動きによって期待通りの音を出せることを目指しています。 音に合わせて体を動かすのではなく、体の動きで音を作り出すことの出来るような、新しい表現方法の創出を目指しています。 |
| 動的な形状表現が可能な立体ディスプレイに関する研究 本研究では、物理的に立体形状を表現し、動的な形状表現によって立体のアニメーションも表現可能なディスプレイについて研究を行います。 立体ディスプレイの実現には、動的に立体形状を表現する機構を持つハードウェアを作成し、表現された形状に対しプロジェクタを用いてテクスチャをマッピングする必要があります。 さらに、操作時に影のできない立体ディスプレイを実現しました。 これまでの立体ディスプレイに関する研究では、ディスプレイ上方に設置されたプロジェクタからディスプレイ表面に投影を行っていました。 しかし、この方法で投影した場合、直接インタラクションを行う際に手などが遮蔽物となりディスプレイ表面に影ができてしまいます。 そこで、本研究ではディスプレイに対してリアプロジェクションを行い、影のできない立体ディスプレイを実現しました。 |
 |
 |
人間-コンピュータ間の新たなインタフェースを実現するFRCの研究 新しいHuman-Machine Interfaceとして、Future Robotic Computer(FRC)の研究開発を行っている。FRCは、5台のモータによって2台のカメラ-プロジェクタユニットが可動式になった構造になってい る。この構造によって、従来のタッチパネルなどに比べて、広範囲で入出力を行ったり、投影によって実物体に直接情報を重畳したりできるなど、より自由度の 高いインタフェースが実現できる。 現在、FRCへの入力インタフェースとして、R-Penの研究を行っている。R-Penは、一定の周期でペン先の赤外線LEDが点滅する、といった単純 かつ安価に実現可能な仕組みとなっている。FRCのカメラによってこの点滅を認識することにより、R-Penによる入力を実現する。 |
| テレオペレーションにおける非熟練者のための操作性向上インタフェース開発 地震などの災害が発生した場合、私達は避難を優先しなければならない状況に置かれ、建物内には貴重品や思い出の品などが残されることになる。それらを取 りに行こうとしても、二次災害の恐れがあり、立ち入り禁止になる場合がある。個人でロボットを所有し、ロボットを遠隔操作するテレオペレーション技術を用 いることで、人は安全な場所から被災地の探索や物品回収などの個人の願望を叶えることが可能となる。しかし、ロボットを直接見て操作できないテレオペレー ションは、ロボット操作に慣れていない人にとっては困難である。そこで本研究では、ロボットを初めて操作する人でも容易に操作が行えるように、様々なイン タフェースを開発している。 |
 |
過去の研究テーマ |
|
| 人間の曖昧な記憶でも検索可能な画像検索アルゴリズム 情報技術の進化に伴う画像数の膨大化や、人間の記憶の曖昧性によって、後に個人の所有する画像を見つけ出せないという問題が発生する。そのため任意の画像を瞬時に見つけ出すことのできる検索技術が求められている。 まず、画像検索技術は大きく分けて2種類ある。一つはImageGoogleなどで使われている方法であり、Text-Based-Image Retrievalと呼ばれる。他方は、Content-Based-Image Retrievalと呼ばれ、これは画像中の輝度・色情報などの特徴量の分析を行い、検索時に使える情報を抽出して行う検索方法である。本研究では、後者 の方法を用いた画像分析を行い、ユーザは「人数・物体・位置情報・色合い・所有している類似画像」の中から、記憶に残っている任意の項目を指定することで 検索を行う。 |
 |
 |
画像処理による読唇術の再現とマルチモーダル音声認識システムの研究 音声認識が注目されているが、雑音の多い状況下では認識性能が著しく低下してしまうことや、発声が困難な場所では利用出来ないという問題がある。本研究 では、環境に左右されないロバストな入力方式の実現を目的とする。近年、読唇術を画像処理で再現する研究が進められている。これを機械読唇と呼び、カメラ からの映像情報のみで発話内容の認識を行うため、音声雑音などの影響を受けず、発声を必要としないメリットがある。本研究では、音声認識と機械読唇による 認識結果を組み合わせた、より高精度な認識を行うシステムを開発し、ロバストな入力方式の実現を目指す。 |
| 知能化空間を利用した生活情報自動記録 人が自分の生活について憶えていられることは多くない。例えば、昨日家に帰ってから寝るまでの間に何をしていたか憶えているだろうか。一昨日や先週につ いてはどうだろうか。他にも、自分が憶えていると思っていた事が、実は思い違いをしていたという経験はないだろうか。生活記録をブログや写真の形で残す人 は多い。しかし、1日分の記録として、数行の文章や数枚の写真だけで十分といえるだろうか。記録者本人が気づいてさえいない部分に、本当は重要な情報が隠 れている可能性はないだろうか。 そこで本研究では、人の生活を自動記録する手法を提案する。これには2つの利点がある。人が能動的に記録する必要がなくなる点と、記録内容が人の気づき に依存しなくなる点である。よって、本研究では知能化空間内にあるカメラやマイクなどのセンサデータを利用し、人や物体の振る舞いを収集・分析する。これ により、大量の生活記録を自動的に残すことが可能となる。 さらに、大量の生活記録を人にとって理解しやすくするために「視覚化」を行う。適切な視覚化は、情報認識において非常に重要である。例えば、ユーザが本 来気づくことのできないデータの変化を明確にすることは、視覚化において基本原則といえる。視覚化を行うことで初めて、整理されていない大量のデータが ユーザにとって有益となる。 最終的には、ユーザが自身の記録を元に、あらゆる観点から自分の生活を見つめなおすことで、人が自分の生活に関して知覚できる範囲を広げることを可能とするシステムの実現を目指す。 |
 |
 |
音響を用いた人への情報提示 聴覚での情報取得は視覚からで知ることのできない後方などの死角からの情報も取得することができ、また音を聞くことでその場で何が起こっているのかを把 握することもできます。そこで、立体音響を用いて全方位からの情報提示を可能とし、ユーザの捜し物の場所の提示や仮想の音像による人の誘導などのシステム を構築しています。また、音を聞くことで視覚と同等以上の情報を取得するため、“耳でものを見る”ことを目指して視覚と聴覚の関係を研究しています。 |
| ユーザの自然な動作における衣服情報の自動取得と再構成 衣服から、人間の趣味や趣向といった人間内部の情報を読み取る研究をしている。 コンピュータが特定のユーザ個人に合わせたサービスを提供するためには、コンピュータがそのユーザの事を理解する必要がある。また、人間を日々観測・記 録し、そのデータを分析することで、コンピュータは自動でユーザを理解できると考える。そこで本研究ではユーザの着用する衣服を持って、コンピュータに ユーザを理解させ、ユーザ個人に合わせたサービスへの展開を目指すものである。現在ユーザの衣服を自動で取得できるシステムの開発を行っている。 |
 |
 |
アナモルフォーズによる立体映像提示 近年、3D映画やニンテンドー3DSの登場により、立体的な情報提示が注目されつつある。しかし、従来の方法では特殊なデバイスを装着したり視差を利用 して立体視の実現を行なっているため、利用者の目の疲れや3D酔いなどの問題点を抱えている。そこで我々はユーザの身体に負担をかけない裸眼立体視の実現 のために、アナモルフォーズを用いた手法を提案している。 アナモルフォーズとは、一見何が描かれているか分からないが、ある一点から眺めると もっともらしい絵が見えるという描画手法である。アナモルフォーズは絵画だけでなく 彫像や建築にも用いられており、身近なものでは路面に描かれている交通標識などがあ る。本研究ではこのアナモルフォーズを利用し、ユーザの視点から見たときに正常に見 える画像を提示することで立体視を実現させようと試みている。ユーザに見せたい物体 の画像を、アナモルフォーズを用いてわざと歪ませ地面に提示すると、実際にその物体 がその場所に存在しているかのようにユーザに錯覚させることができる。さらに、提示 物体にアニメーションや影を付加することで、より立体感を演出している。 |
| 加速度センサを用いたジェスチャによる個人認証 私のテーマは加速度センサによる個人の特徴を利用した個人認証です。開発したデバイスを用い、空中に文字を書く際の手の動きから誰が書いたのか特定でき るシステムを研究しています。近年情報端末は情報漏洩を防ぐため、個人特有のパスワードで保護しています。しかし、情報を参照するたびに、パスワードを入 力するのは煩雑であり、パスワードを設定しない原因にもなります。現在行っている研究では、動きから本人の特徴がわかり、他人にパスワードが盗まれにく く、少しの動作で認証が行えるため、ユーザは手間を感じなくなります。 |
 |
 |
人物位置・顔認識 私達は、実験室に実際の知能化空間を構築しようとしています。具体的には、知能化空間内において、誰がいつどこにいたか、何を喋ったか、何を触ったかな どを自動的に記録できることを目指しています。その中でも、人物の位置を知ることは特に重要です。 そこで本研究では、知能化空間に入った人物がそこから出るまでの間、どのように移動したかを何人でも同時に追跡・記録し続けられるシステムを作っていま す。複数の人物を同時に追跡するために7台、また同時に全ての人物の顔を識別するために12台の、合計19台ものカメラをネットワークで結び、システムを 構築しています。 |
| 知能化空間における人間無拘束型の個人認証に関する研究 一般的にセンサを用いたコンピュータシステムで実装される個人認証は指紋、虹彩、声紋、顔面、静脈やパスワード入力などユーザは認証センサに対してある一 定時間の拘束状態をよぎなくされます。今研究で目指す知能化空間はより日常生活に近い形で実現することであり、無拘束状態で行われる認証です。大きく異な る点は拘束型ではある程度固定形な認証対象部の情報が入手できるのに対して無拘束型は流動的な認証対象部を想定する必要があります。 この柔軟な変形に対応する為、AAM(Active Appearance Models)を用います。AAMは入力画像に近いモデルを低次元かつ高速に表現することができ、また目や口そして顔全体が変形を伴う場合に柔軟に対応す るモデルを生成することが可能です。 |
 |
 |
再構成容易なテーブルトップ型タンジブルインタフェースの開発 この研究では、ユーザーがいつ、どこでも直感的な操作が可能なインタフェースを目指しています。これを実現するために、テーブルトップ型のタンジブル ユーザーインタフェースについて研究を行っています。このインタフェースでは、ひとつの操作領域を複数人で共有することで、コミュニケーションの促進、そ れによる新たなインタラクションなどが望めます。従来手法ではユーザーの操作検出のために特別な机が必要であり、そのため操作領域は縛られていました。本 研究では新たな位置検出手法を開発することで、ポータブルで任意平面において利用可能なインタフェースを実現します。また、インタフェースは小型ながら入 力に対し様々なフィードバックを提示することで、多彩な表現が可能になります。 |
| テレオペレーションにおける操作性向上のための把持操作インタフェースの研究 テレオペレーションと呼ばれる、ロボットを遠隔操作する技術が宇宙開発や被災地などの場面で利用されています。人の代わりに作業を行うロボットには、物を掴ませるという動作は必須であると言えます。 例えば被災地において、初心者がロボットを簡単に扱うことができれば、迅速な対応が必要な場合や、レスキュー隊の手の回らない場面においても人の安全を確保しながら活動することが可能です。 初めてロボットを利用する人でも、ロボットで物を掴めるように、レバー操作などではなく、日常的に行う親指と人差し指によるつまみ動作で操作するインタフェースの開発を行っています。 物を掴んだ感覚とその重さを操作者に提示することで、自分が物をつまんでいる感覚でロボットの把持動作を操作できます。 |
 |
 |
力覚提示を用いたテレオペレーションの研究 現在、多くの分野で遠隔操作ロボットが活躍しています。この技術は、例えば二次災害の危険性がある被災地や、宇宙開発の分野において利用されています。 人が遠隔地からロボットを操作することにより安全かつ円滑に作業を遂行することができます。 遠隔地からロボットを操作する場合、カメラ画像を頼りに行なうことが多いのですが、カメラ画像のみでの操作は距離感が掴みづらく、また画像データ量の多さにより生じるタイムラグにより操作が難しいという問題があります。 これらの問題を解決するため力覚情報を利用し、遠隔操作ロボットの操作性を向上させる研究を行なっています。 |
| モーションキャプチャを用いた、社交ダンスにおけるウォーク中のポイズの抽出と評価 社交ダンスを先生から教わり練習する際、時間の都合がつかない場合や、練習場所が遠いといった物理的な理由で練習がやりにくい場合があります。また、教 わる場合には先生の主観が入ることや自主練習では、第三者視点からの解析ができません。 こういった理由から、自分で練習場所を構築でき、定量的な判断ができるよう、PCとモーションキャプチャシステムを利用した社交ダンス指導システムの構築を目指します。 今段階では、社交ダンスのラテンアメリカン種目で用いられる基本姿勢「ポイズ」を独特の歩く動作「ウォーク」から抽出し、評価するシステムを開発しまし た。表示される3DCGによる画面には動作を入力したデータとお手本のポイズが入力されています。 ウォーク中にポイズが検出された場合、色が変化します。動作は止めることができ、入力したポイズとお手本のポイズを見比べることができ、テキストベースで解析結果が出力されます。 |
 |
 |
骨伝導波を用いた物体との接触時におけるユーザの識別 近年の、身の回りに何かしらのコンピュータが存在する社会(ユビキタス・コンピューティング)において、ユーザが個人の好みに合ったサービスを受け取る には個人の識別が重要です。現在社会で主に活躍している個人識別システムは例えばRFID等がありますが、このような非接触型の個人識別システムには、情 報の漏えいや誤作動の問題が存在します。 そこで、骨伝導波を使うことで完全な接触による個人識別システムを開発しこれらの問題に対応します。 |
| 空間知能化における空間アバターに関する研究 知能化空間内で人間とインタラクションを行う空間のアバターを開発します。人間が知能化空間と直接会話を行うにはまだ抵抗感を感じる可能性が高いです。 そこで、人間と似たような形をしている知能化空間のアバターが空間の代わりに人間とインタラクションを行います。 人間と似た格好をしているため人間のようなジェスチャーができ、機械的な音声による会話だけじゃなく身振り手振りを交えた表現豊かなインタラクションが可能です。 |
|
 |
インテリジェントモジュールの提案・設計および制作 知能化空間のリソースとして持つべき機能として、インテリジェントモジュール(Intelligent Module)の提案・設計および制作を行います。 インテリジェントモジュールとは、リソース、ネットワーク機能を持つ知的デバ イス間のインターフェイスの役割をするものです。 また、ネットワーク接続機能だけでなく図のような様々な機能を持ち、制御命令を受けて実行するだけでなく、リソースの持つ機能や情報を知的デバイスに提示することによって、より簡単で的確な制御を可能にします。 |
| 知能化空間におけるタスク・スケジューリング 空間内にある様々なリソース(家電機器、メディア、コンテンツ、配線など)を人間の要求に応じて組合せ、制御するしくみに関する研究です。例えば空間内 にいる人が本日のニュースを見たいと要求したとしましょう。知能化空間はまず、空間内にこの要求を満たすためのリソースがあるかを確認します。もし要求を 実現するに十分なリソースがあれば、どのような組合せでどのようなタイミングでリソースを動かすかを計画しなければいけません。これが本研究の課題です。 |
 |
 |
音声認識・理解 私たちは、何気ない会話から相手の要求を理解できますが、コンピュータには大変です、本研究では、日常生活における会話や、「熱いね・・」など自然にで る独り言などをコンピュータが理解する事を目標としています。音声認識は、空気の粗密をマイクが受音し、音声波形より尤もらしい言葉を選び出すことで行い ます。しかし音声波形に雑音が混入すると、正しい言葉を得ることが難しくなります。 1つの解決方法として、携帯電話やヘッドセットなどのデバイスの利用が考えられますが、日常生活で常にデバイスを装着することは、大きな負担となり現実的 ではありません。 本研究では、束縛の無い人間中心のシステムを実現するため、適応型ブラインド音源分離システム構築に取り組んでいます。コンピュータの言葉理解を促進 し、将来は、知能化空間内で他のモジュールと連携することにより、さまざまな要求に応えるサービス実現を目指します。 |
| 打力による球形物体の回転運動を用いた目標位置接近 近年、日本でも防災に対する関心が高まっている。現在様々な防災に関する技術が存在するが、その一つの方法として、センサネットワークの設置を挙げる。 そのセンサネットワークを地球上に配置することにより、地球環境を観察することが可能になり、防災にもつながるのである。 しかし、センサネットワークの設置において、人間による配置が危険な場所が存在するなどの問題が挙げられる。その問題の解決方法として、離れた場所から センサに力を加え、目標位置へ設置するという方法を提案する。離れた場所へ力を加えてセンサを設置するにも、様々な方法があるが、本研究では、センサを目 標位置まで転がすことを目標とする。そこで、センサをゴルフボールに置き換え、転がすための機構の研究・開発を行う。 |
 |